- Virtualization: virtual box 같은 프로그램을 어떤 방법을 사용해서 빠르고 쉽게, 버그 없이 구현할수 있는가를 os 차원에서 지원하는 것을 의미.
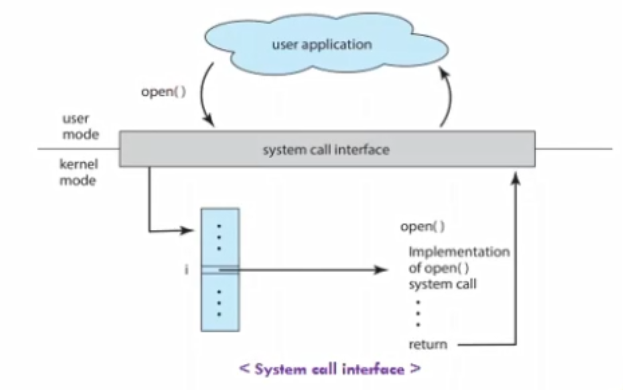
System call
- OS에서 제공하는 서비스에 대한 프로그래밍 인터페이스 - 전형적으로 고급언어로 쓰여졌다. (C or C++)
- 대부분 직접적인 시스템 호출이 아닌 고급 API(응용프로그램 프로그래밍)를 통해 프로그램에 의해 액세스된다.
- Win32 API for Windows, POSIX API for POSIX-based systems, JAVA API for the JAVA virtual machine
- 하드웨어를 직접적으로 다룰 수 없으니, 다루면 너무 비효율적이니 OS에 이를 위임하고 하드웨어를 직접 다루는 영역
- 내가 하드웨어에 접근하려면 System call을 부른다.
Process Concept
■ Program (프로그램)
- 하드디스크 혹은 스토리지에 존재하는 우리가 만든 바이너리 파일
■ Process (프로세스)
- 프로그램을 실행시켜서 메모리에 수행될 수 있는 상태로 올라가 있는 코드 (= a program in execution)
└ 왜 이렇게 하는가? : CPU는 구조상 모든 명령어와 데이터는 메모리에 있어야한다. 하드에 있는 데이터와 명령어는 실질적으로 바로 실행이 불가능하기 때문이다. 이 과정을 통해 프로세스가 만들어진다.
- 프로세스 실행은 순차적 방식으로 진행되야 함. - 단일 프로세스의 명령어가 병렬로 실행되지 않음
프로세스 하나가 메모리에 올라가면, 이 표와 같이 메모리를 차지한다.
text = code.
data= global/static data: 프로그램이 시작했을 때 어떤 데이터가 어디 저장될지 미리 알 수있는 것.
heap: 동적으로 할당.
stack: function call을 할 때 사용.
※ 실제 이 상태로 메모리에 올라가는 것은 아니다. advance tanslator를 통해 paging을 통해 쪼개져 메모리에 올라감. 단, 프로세스는 만들어질 때 실제 메모리와는 무관하게 철저히 프로그래머 입장에서 이렇게 됐을거라 생각하고 프로그램을 짜면 된다.
■ Memory layout
- 임시 데이터를 포함하는 스택(함수 매개 변수, 반환 주소, 지역 변수)
- 데이터 섹션은 전역 변수를 포함. - 힙에 런타임 동안 동적으로 할당된 메모리가 포함.
Q: 메모리가 있으면 주소가 있는 것. 사용자가 어떤 프로세스를 만들면, 0번지(맨아래)부터 올라가게 되는데 이 주소는 물리적 주소인가 가상적 주소인가?
Process State
New: 프로세스 생성되고 있음. Running: 명령이 실행 중. Wating: 프로세스가 어떤 이벤트가 발생하기를 대기. Ready: 프로세스가 프로세서에 할당되기를 대기. Terminated: 프로세스 실행이 완료
new에서 생성이되면, ready 큐로 가서 준비를 함 (Process Scheduler가 선택할때 타깃이 될 수 있는 준비) > 스케줄러가 스케줄러 알고리즘을 통해서 CPU에 실행해도 된다고 알림 (이 과정이 dispatcher) > 실제로 running 단계에서 프로그램이 CPU에서 돌아감 > ⓐ/ⓑ
ⓐ Interrupter가 걸려서 내 의지가 아닌것으로 끊기거나 나에게 할당된 시간을 다 사용해서 ready 큐로 가서 대기
ⓑ 프로그램을 수행하다가 프로그램 내에서 I/O 혹은 event를 기다려야한다고 선언을하면, wating으로 감. I/O, event가 발생하면 ready큐로 감. 이후 내 순서가 되면 수행이 됨
- 실질적으로 OS가 Ready Queue를 관리하는건, 스레드이다.
- 때문에 멀티스레드 환경일 경우 눈에 보이는 순서로 실행되는게 아닌, 위의 표와 같은 순서로 빙빙 돌기 떄문에 어떤 스레드가 언제 어떤 방법으로 수행될지 알 수 없다. (인터럽트가 걸리던, 타임 슬라이스가 끝나건 이유 막론하고 전부 ready queue로 모이기 떄문에 어떤 프로세스가 어떤 순서로 실행될지 알 수없다는 것)
※ 프로세스 코어는 한 순간에 하나의 프로세스만 실행함.
Context Switch
CPU가 프로세스 하나를 수행하다가 일정 시간이 지나면 그 state를 버리는것이 아니라 수행하는데 필요한것을 모두 모아 다른곳에 일시적으로 저장했다가 다른 프로세스를 다시 읽어들여 실행하는 것. (번갈아가며 수행해서 마치 프로세스가 동시에 수행되는 것처럼 보이게하는 것)
■ CPU가 다른 프로세스로 Swithcing할때 반드시 해야하는 것
- old porcess의 상태를 저장해야한다. (save the state of the old process)
- 새로운 프로세스를 위해 저장된 상태를 불러온다 (Load the saved state for the new process)
■ 단, Context Switch는 Pure Overhaed.
- 전환하는 동안 시스템이 유용하게 작동하지 않는다. - 대응력과 처리량 사이의 균형을 유지한다. (trade off between responsiveness and throughput)
Process Creation
- 제일 처음에 만들어진 프로세스를 제외하고 모두 프로세스의 자식일수밖에 없다. 이 프로세스들의 고유한, 어떤 프로세스인지 알려주는것이 PID이다.
※ 같은 프로그램이라도 처음 실행할떄, 다음 실행할때 PID가 각각 다르다.
■ 프로세스가 다른 프로세스를 생성
- 부모/자식 프로세스
- 프로세스 트리 형성
■ 일반적으로 프로세스 식별자를 통해 식별 및 관리되는 프로세스 (PID)
- 프로세스에 액세스하기 위한 고유 값
■ Fork
fork 는 원래 실행되던 프로세스의 복사본이다. 최초의 프로세스를 부모 프로세스라고 하고 fork 되어서 만들어진 프로세스를 자식 프로세스라고 한다. 자식프로세스는 fork 를 실행한 부모프로세스의 기존 구조를 그대로 가져온다. 그리고 두 개의 프로세스는 동시에 실행된다. 하지만 fork로 새로 만들어진 자식 프로세스는 자신만의 pid를 가지게 된다.
fork 이후에 내가 구현하지 않은 없는 코드를 만들기 위해서는 exe 계열의 execlp를 사용해 시스템콜을 통해 다른 프로그램으로 갈아버려야한다.
이렇게 fork를 하면, 부모프로세스는 자식 프로세스를 기디린다. > wait(NULL)
■ 부모 프로세스 종료 대기
- 상위 프로세스는 wait() 시스템 콜을 사용하여 하위 프로세스의 종료를 기다릴 수 있습니다.
- 호출은 종료된 프로세스의 상태 정보와 pid를 반환. > pid = wait(&status);
※ 부모 프로세스가 이유를 막론하고 wait를 수행하지 않으면 부모 프로세스가 살아있는 동안엔 자식프로세서는 좀비 프로세서스가 된다.
※ wait() 프로세스를 호출하지 않고 종료된 상위 항목이 고아인 경우 init 프로세스가 새 부모로 할당됨
Thread
■ Amdahl's Law (중요)
- 느린 프로세스를 speed up 하려면 가장 문제가 되는 구간을 찾아 성능을 향상시키면 좋겠다. (이를 조금이나마, 대략적으로라도 측정하기 위해 사용하는 것) = 컴퓨터 시스템의 일부를 개선할 때 전체적으로 얼마만큼의 최대 성능 향상이 있는지 계산하는 데 사용
- 직렬 및 병렬 구성요소를 모두 갖춘 애플리케이션에 코어를 추가하면 성능이 향상됨.
- 모든 프로그램은 시리얼(Serial), 페레럴(Parallel)로 나눌 수 있다. 프로그램을 수행하다보면 CPU가 여러개건 하나건 어차피 하나의 CPU로 수행되어야하는 일이 있다. (사용자의 입력을 받는 경우:로그인)
- 반대로 무거운 workload가 있어 혼자 수행하기 힘드니까 일(job)을 명확히 나눠서 다시 끝난 결과를 모아 새로운 결과를 만들면 성능이 좋아지는 케이스 (병렬화)
프로그램을 직렬로: S
직렬이 아닌 부분(CPU 갯수를 늘릴수록 일을 빨리 끝냄): (1-S)
■ Thread
- 프로세스(process) 내에서 실제로 작업을 수행하는 주체를 의미
- 프로세스 하나엔 여러개의 스레드가 있을 수 있다 > 멀티스레드 > 실질적으로 이 스레드가 스케줄링의 단위가 됨.
- 대표적으로 다음 그림에서 code, data를 공유하게 됨.
- 프로세스를 바꾼다는것 > Memory layout을 통채로 갈아치운다는 의미.
- 프로세스가 사실 프로그램을 실행하는 기초단위이다 (과거)
- 코드 섹션, 데이터 섹션 그리고 열린 파일과 신호와 같은 다른 자원들과 같은 동일한 프로세스에 속한 다른 스레드들과 공유한다.
※ 달라야하는 부분만 따로 분리해서 PC(Program counter), Stack, Register를 따로 관리할 수 있도록 해놓은 것을 스레드라고 함.
CPU Scheduling
CPU가 비어있게 되면 Ready 큐 중 하나를 선택해 수행해야하는데 그 과정을 CPU Scheduling (=Process Scheduling, Process Management)이라 일컫는다.
NonPreemtive (비선점형)
- 내가 놓지 않으면 CPU를 빼앗기지 않음
- 프로세스가 CPU를 방출할 때까지 프로세스를 제거할 수 없음. - CPU가 프로세스에 할당되면 프로세스는 종료 또는 대기 상태로 전환하여 CPU를 해제할 때까지 CPU를 유지.
Preemtive (선점형)
- 중간에 내가 원하지 않아도 수행되고 있는 CPU를 빼앗김.
- 프로세스가 실행 중에 제거될 수 있음. - 사실상 윈도우, MAC, LINUX/UNIX를 포함한 모든 최신 운영 체제는 사전 스케줄링 알고리즘을 사용함.
■ First Come First Served (FSCS)
프로세스가 들어오거나 수행될 준비일 때 이것들을 어떻게 배치하느냐에 따라 성능이 좋아질수도 나빠질수도, 사용자 입장에서 답답할수도 그렇지 않을수도있는 상황이 벌어짐.
■ Shortest Job First (SJF)
제일 빨리 끝날것 같은 프로세스를 먼저 수행하는 알고리즘.
프로그램이 시작할떄 Process가 이미 ready 큐에있고 얼마나 수행될지 (Burst Time) 알고있는 상태에서 쓸 수 있다.
■ Shortest Remaining Time First
SJF의 Preemtive (선점형) 버전.
각각 들어오는 시간 (Arrival Time)이 달라서 사용자가 수행하고 있는데 새로 무언가가 들어왔을때 새로 계산해서 무엇을 수행할지 결정하는 알고리즘.
Synchronization
■ Race Condition (중요)
- 여러 프로세스 혹은 스레드가 동일한 데이터에 지속적으로 액세스하고 실행 결과는 액세스가 발생하는 특정 순서에 따라 달라짐 > 사용자가 의도하지 않은 결과가 나타남.
- 동기화가 필요함 > Race Condition을 방지하기 위해 한 번에 하나의 프로세스만 공유 데이터를 조작함.
- 멀티 코어 시스템의 중요성 증대 > 멀티스레드 응용프로그램은 서로 다른 프로세싱 코어에서 병렬로 실행됨 - OS는 많은 커널 모드 프로세스가 활성 상태이기 때문에 가능한 여러 Race Condition에 따름.
※ Race Contidtion을 방지하기 위해서는 같은 데이터를 쓰고있는 것들 간의 씽크를 맞춰주는 Synchronization이 필요하다.
■ Critical Section
- 프로세스가 공유 데이터에 액세스하거나 유지보수하는 코드 세그먼트
- 각 프로세스에는 코드의 중요한 섹션 세그먼트가 있음.
프로세스가 테이블 쓰기 파일 등을 업데이트하는 공통 변수를 변경할 수 있다.
한 프로세스가 임계 섹션에 있을 때 다른 프로세스가 임계 섹션에 있을 수 없음.
- 중요한 부분 문제는 이것을 해결하기 위한 프로토콜을 설계하는 것이다. - 각 프로세스는 입력 섹션에 중요 섹션을 입력할 수 있는 허가를 요청해야 하며, 종료 섹션이 있는 중요 섹션을 따라간 후 나머지 섹션을 따라갈 수 있습니다.
공유 데이터, 사용하는 코드들을 Critical Section 안에 몰아 넣음.
Critical section에서는 공유 데이터를 수정하거나 작업하니까 이 안에서만 작업해라. 대신 이 안에선 딱 하나만 들어와서 작업할 수 있다. > Data에 대한 consistency가 맞기 때문에 Race Condition을 해결할 수 있다.
위의 개념에서 발전해 Progress, Bounded waiting에 대한 문제점을 만족(해결)해야하는 경우가 Critical Section에 대한 문제를 해결했다고 말할 수 있다.
■ Critical Section Problems
mutual exclusion
progress
- 만약 어떤 프로세스도 그것의 ciritical section에서 실행되고 있지 않고 여기에 그들의 critical section으로 들어가기를 원하는 일부 프로세스가 있다면, 다음에 critical section으로 들어갈 프로세스의 선택을 무기한 연기할 수 없다.
- 교착 상태 또는 라이브록 방지
bounded waiting
- 한 프로세스가 해당 중요 섹션에 진입하도록 요청한 후 해당 요청이 승인되기 전에 다른 프로세스가 해당 중요 섹션에 진입할 수 있는 횟수에 제한이 있어야 함. - 기아 방지
※ Peterson's Soultion은 소프트웨어적으로 혹은 알고리즘적으로는 제대로 동작하지만 최신 CPU로 오면서 Peterson's 알고리즘이 동작할 수 있는 전제가 깨짐 > 프로그램이 반드시 순서대로 수행되는 것이 아니기 때문이다. 현재의 CPU들은 상황을 봐서 순서를 바꿔 수행하기도 함 (out of execution)
※ 순서를 바꿔 수행하는 경우를 막기 위해 사용하는 것이 Synchronization Hardware.
- 동기화를 지원하는 세 가지 하드웨어 명령 └ Memory Barriers / Hardware Instructions / Atomic Variables
※ Memory Barrier (Memory fense)
- 다른 프로세스, CPU들간의 Synchronization을 깨는 문제를 방지해준다.
memory_barrier(); 를 치면
x = 100;
flag = true;
위의 두 코드가 관계가 없으면 바꿔서 수행이 가능하지만 memory barrier를 통해 앞뒤로 순서를 아무리 바꾸어도 수행이 불가능하도록 한다.
Q: out of execution 상태에서 <Thread 1>의 memory_barrier(); 코드가 없으면 왜 동작하지 않는가? 있다면 왜 동작하는가?
Q: memory_barrier(); 코드가 <Thread 0> <Thread 1>에 하나씩, 왜 두개가 있어야 하는가?
※ 구체적으로 다음과 같은 명령어를 사용한다. ( Test and Set, Compare and Set )
- Test and Set -- Compare and swap -
■ Mutex [Mutex exclusion] (중요)
상호 배제, 어떤 공유 데이터가 있을 때 a가 쓰고 있으면 b가 사용하면 안된다.
- 이전 솔루션은 복잡하고 일반적으로 응용프로그램 프로그래머가 액세스할 수 없음. - OS 디자이너들은 중요한 부분 문제를 해결하기 위한 소프트웨어 도구를 만듦.
> 가장 간단한 것 = 뮤텍스 잠금. └ 잠금을 사용할 수 있는지 여부를 나타내는 부울 변수
> 하지만 이 해결책은 busy waiting이 필요. └ 스핀록
사용법:
Mutex가 존재하고 라이브러리 형태로 주어지면 critical section 코드 전에
① acquire lock 코드를 통해 Mutex 걸음 (lock을 걸음)
② release lock 코드를 통해 section이 끝나면 lock을 풀어줌
Deadlocks [교착상태]
■ Dining Philosophers Problem
- Deadlock, Starvation과 연관이 있음.
ex)
원형 테이블에 사람 5명이 있고 가운데 밥이 있으며 한사람당 그릇과 젓가락이 하나씩 놓여져있다.
각자 자신의 오른쪽에 있는 젓가락을 잡고 다른 사람이 젓가락을 놓길 기다린다. (젓가락 하나론 밥을 못먹기 때문)
결국 아무도 못먹고 굶어 죽었다.
5명의 사람: 공유 데이터
가운데의 밥: Data set
Semaphore 젓가락 [5] [1]로 초기화
※ 엄밀히 Deadlock과는 관련이 없는데, 한 process가 우선순위에 밀려서 진행이 안됨 > starvation 현상으로 죽음 (수행이 안됨) > 이 문제를 해결하기 위해 우선순위를 올려주는 aging 기법을 사용함.
※ Starvation(중요)
- 무한 대기
- 낮은 우선순위 프로세스가 자기보다 높은 우선순위 프로세스에 밀려 수행할 수 없는 상황.
- 해결책: aging
※ aging
- 시간이 지나면 낮은 우선순위 프로세스의 순위를 높여줌
■ Necessary Conditions for Deadlock (데드락을 위해 필요한 조건)
Mutual exclusion [상호배제]: 한 번에 하나의 스레드만 리소스를 사용할 수 있다.
Hold and wait: 하나 이상의 리소스를 보유한 스레드가 다른 스레드가 보유한 추가 리소스를 획득하기 위해 대기한다. (교수님 말씀= 내가 어떤 리소스를 잡으면 내 일을 다 하기 전까지 절대 놓지 않는다)
No Premmption: 자원을 선점하지 않으며 스레드가 작업을 완료한 후 리소스를 보유하는 스레드에 의해서만 리소스를 자발적으로 해제할 수 있음.
Circular wait [상호대기]: 내가 필요한 것이 상대방에게 있고 상대방에게 필요한 것이 나에게 있을 경우 그 상황을 해소할 수 없는 상황.
※ 위의 네가지 조건이 맞아 떨어지면, Deadlock이 발생한다.
■ Resource Allocation Graph
(a) / (b)
내가 필요로하는 resource, 내가 잡고 있는 resource를 그래프로 그림.
T 사이에 사이클이 생기면 상호대기가 걸림. > 내가 필요한 것이 상대방에게 있고 상대방에게 필요한 것이 나에게 있어 둘 다 놓을 수 없는 상황이 발생. 이를 통해 Deadlock이 걸렸다는 것을 파악할 수 있음.
※ 그래프에 Cycle이 포함되어 있고 각 리소스 유형에 리소스의 인스턴스가 하나만 있으면 Deadlock 발생.
File Systems
■ File Operations [파일작업]
Create / Write / Read
Reposition within file (파일 내 위치 변경)
Delete
Truncate (자르기)
Open: 디스크의 디렉터리 구조를 검색하고 입력 내용을 메모리로 이동.
Close: 메모리에 있는 내용을 디스크의 디렉터리 구조로 이동
■ Open Files
Open file table
- 파일 작업이 필요한 경우, 해당 파일은 색인을 통해 이 테이블에 지정됨.
└ 검색 필요 없음.
File open count -파일이 열린 횟수 카운터
└ 마지막 프로세스가 열린 파일 테이블을 닫을 때 열려 있는 파일 테이블에서 데이터를 제거할 수 있도록 허용
파일을 연다는 것:
os에서 파일을 관리하는 structure가 있고, 파일을 열려고 시도하면 실제로 해당 파일은 메모리가 아닌 스토리지에 존재하는데 (CPU는 메모리에 있어야 접근이 가능함) 파일들의 데이터를 사용자가 사용 가능하도록 잘 조합해 구조체 혹은 테이블 형태로 가지고 있어 사용자가 파일에 접근할 경우 읽고 쓰기 쉽게 만들어준다.
※ 열려진 파일에 대해 카운팅을해서 누군가 그 파일을 열고있으면 구조체를 유지. 없으면 파일을 없앰.
사용자가 파일을 열면 그것은 Storage에 존재하는데, User space에서 Secondary storage로 연결되는게 아니라,
중간에 관리 역할의 구조체 테이블 (direct structure)이 흩어져있는 조각들 (secondary storge 내에 있는 것들)을
모아서 사용자에게 전달해준다. 이 과정을 거쳐 사용자는 파일을 편리하게 사용할 수 있다.
■ Directory Structure
파일 이름을 파일 제어 블록으로 변환하는 기호 테이블
Directory Operations
Search for a file - 특정 파일의 항목을 찾는다.
Create a file - 새 파일을 만들고 디렉터리에 추가해야 한다.
Delete a file
- 파일이 더 이상 필요하지 않으면 디렉터리에서 제거된다.
List directory - 디렉터리에 있는 파일과 각 파일의 디렉터리 항목 내용을 나열함.
Traverse the file system - 디렉토리 내의 모든 디렉토리와 파일에 접근한다.
※ OS에서의 디렉토리는 파일을 관리하는 또 다른 단위이다. 단순히 파일을 모아놓는것이 아닌 파일의 구체적인 데이터를 가지고 있는 파일 관리 단위 중 하나이다.
■ File System Layer
A라는 파일을 열면, 그 파일이 어느 디렉토리에 있는지 찾음. > 그 디렉토리에서 logical block을 physical block으로 변환. > physical block을 실제로 저장되어있는 하드의 몇번째 실린더의 몇번째 블럭인지 알아야함. > 하드에 구체적으로 명령을 줌.
위와 같이 굉장히 복잡한 과정인데 이것이 파일 시스템 내에 존재해서 우리 대신 수행해주기 때문에 우리는 쉽게 파일 사용이 가능하다.
int chmod (const char *path, mode_t mode); int fchmod (int fd, mode_t mode);
파일엔 permission이 존재해 아무나 접근이 불가능하다.
File mode
S_ISUID (04000) set-user-ID S_ISGID (02000) set-group-ID S_ISVTX (01000) sticky bit
S_IRUSR (00400) read by owner S_IWUSR (00200) write by owner S_IXUSR (00100) execute/search by owner
S_IRGRP (00040) read by group S_IWGRP (00020) write by group S_IXGRP (00010) execute/search by group
S_IROTH (00004) read by others S_IWOTH (00002) write by others S_IXOTH (00001) execute/search by others
위와 같은 mode들로 접근이 가능하다.
USER/GROUP/OTHERS * read, write, execute 크게 9가지의 권한이 있다.
permmision을 주면 파일이 사용 가능하다.
■ Current Working Directory (실습을 통해 진행함. 시험에 나올수도?)
getcwd()
#include <unistd.h>
char * getcwd (char *buf, size_t size);
현재 작업 디렉터리의 절대 경로 이름을 가져온다. - 상대 경로 이름의 시작점
값 반환 - 성공: 경로 이름을 바이트 길이의 buf로 복사하고 포인터 buf를 반환.
- 에러: NULL 반환하고 errno set.
chdir()
#include <unistd.h>
int chdir (const char *path); int fchdir (int fd);
- 현재 작업 디렉토리를 경로로 변경한다. - 로그인 후 첫 번째 현재 작업 디렉터리가 /etc/passwd에 지정된 대로 설정됩니다.
값 반환
- 성공: 0 반환.
- 에러: -1 반환하고 errno set
mkdir()
#include <sys/stat.h> #include <sys/types.h>
int mkdir (const char *pathname, mode_t mode);
- 디렉토리를 생성.
- mode 인수는 새 디렉터리에 대한 사용 권한을 지정한다.
값 반환
- 성공: 0 반환.
- 에러: -1 반환하고 errno set.
rmdir()
#include <unistd.h>
int rmdir (const char *pathname);
- 비어 있어야 할 디렉토리를 삭제. - rm 혹은 -r과 같은 재귀 삭제 옵션은 없다.
값 반환
- 성공: 0 반환.
- 에러: -1 반환하고 errno set.
opendir()
#include <sys/types.h> #include <dirent.h>
DIR *opendir(const char *name); DIR *fdopendir(int fd);
- 디렉토리 이름에 해당하는 디렉토리 스트림을 엽니다.
값 반환
- 성공: 디렉터리 스트림에 대한 포인터를 반환합니다.
- 에러: NULL 반환하고 errno set.
※ 디렉터리 스트림: 오픈 디렉터리를 나타내는 파일 설명자와 일부 메타데이터 및 디렉터리 내용을 저장하는 버퍼를 포함.
readdir()
#include <sys/stat.h> #include <dirent.h>
struct dirent *readdir (DIR *drip);
- 디렉토리를 읽음.
값 반환
- 성공: drip의 다음 디렉터리 항목을 위해 dirent 구조로 포인터를 회전시킵니다.
- 에러: NULL 반환하고 errno set.
- 디렉토리 스트림 끝에 대해 NULL 반환
closedir()
#include <sys/stat.h> #include <dirent.h>
int closedir (DIR *drip);
- 디렉토리를 닫음.
값 반환
- 성공: drip의 다음 디렉터리 항목을 위해 dirent 구조로 포인터를 반환합니다.
- 에러: -1 반환하고 errno set.
struct dirent
struct dirent { ino_t d_ino; // inode 번호 off_t d_off; // offset이 아님, 아래 참조 unsigned short d_reclen; // 이 record의 길이 unsigned char d_type; // 파일유형, 일부 파일 시스템 유형에서 지원되지 않음 char d_name[256]; // NULL로 종료된 파일 이름
POSIX.1에 의해 위임된 필드는 d_name, d_ino뿐이다.
- example -
■ Hard Links & Symbolic Links (soft links)
모든 파일은 Inode를 통해 관리가 된다.
파일을 생성하면 directory 내에서 파일 이름(file 1)과 Inode를 연결해준다.
또 다른 파일 이름(file 2)를 만들고 file 1에 대한 Hard Link를 만들었다고 가정하면, 새롭게 Inode를 가리키는 Link가 생긴다.
Hard Link가 없어지면 Inode도 사라진다.
Q: 이 상황에서 vi editor를 사용해 File 1의 내용을 수정했다. 그 후 File tool을 열어봤다. 그렇다면, 수정된 내용이 보이는가 안보이는가?
A: Hard Link의 경우: File 1을 열어서 바꿈 > 내용이 바뀜 > inode를 통해 실제 FIle content가 바뀌기 때문에 > File 2도 열면, 같은 inode를 공유하기 때문에 File content로 접근 > File 1을 바꾸면 File 2도 바뀜
A: Copy의 경우: File 2를 copy 하면 새로운 inode가 생겨서 Hard link가 걸리고 File content가 복사된다. > FIle 1을 열어서 아무리 바꾸어도 File 2에는 아무런 영향이 없다.
A: Symbolic link의 경우:
File 1에 대한 File 3의 Symbolic link를 생성함 > File 1과 File 2는 같은 Inode를 바라본다. > 엄밀하게 File 1과 File 3는 다르다 > FIle 3는 독자적인 Hard Link와 독자적인 Inode를 가지고 있다. > 다만 FIle content 자체가 File 1을 가리키고 있다는 것을 의미한다. > FIle 3를 수행하면 OS는 Inode를 찾아서 FIle content를 찾아간다. 이것은 File 1을 가리키고 있으며 OS가 재해석을 해서 File 3는 File 1이구나 라고 생각함. (그냥 window의 바로가기 개념이라고 생각하자)
Virtual Memory(1)
OS의 핵심은 커널이고 커널의 핵심은 Process Management, Memory Management이다.
※ 핵심
같은 physical memory에 프로그램을 여러개 넣으려면 User program 1, 2의 physical address는 달라야하는데 프로그램을 짤 때 이 문제를 전부 고려할 수 없다. Single Programming 상황에서는 모든 프로그램을 프로그래머가 사용하기 때문에 프로그래머가 전부 관리할 수 있지만 multi Programming 상황에선 프로그래머가 실제 어느 메모리에 올라갈지 모르기 때문에 가상 주소만 사용한다. 모든 메모리를 프로그래머가 쓰는 상황인 것 처럼 프로그램을 만들고 physical memory 영역에 매핑 시킨 후 관리해주는 것을 virtual memory라고 한다.
Address Translation
Virtual address를 Physical Address로 바꾸는 과정 (MMU)
하드웨어(CPU)에 존재 CPU만 가지고는 완벽하게 동작하지 못하며 OS가 관여해줘야 한다.
※ Address Translation을 해주는 과정: Memory Managemeny Unit (MMU)
■ Memory Protection
같은 메모리에 여러개의 프로그램이 올라가야하니 다른 메모리 영역을 침범하면 안되기 때문에 만들어짐. 기초적으로 base, base + limit를 사용한다.
- 한 쌍의 기본 레지스터와 제한 레지스터는 프로세스의 논리적 주소 공간을 정의. - CPU는 사용자 모드에서 생성된 모든 메모리 액세스를 검사하여 base와 limit f 또는 해당 사용자 사이에 있는지 확인해야함. (다른 메모리 공간에 대한 액세스로 인해 trap이 발생: <memory protection with base/limit registers> )
- Base/limit Register
프로그램을 process(P1, P2, P3)에 넣을 때 base와 limit를 걸어서 Process는 420940 `~ 300040 영역까지만 수행 가능하도록 영역을 지정해주는 것.
- Memory protection with base/limit register
CPU가 Process2(P2)를 수행할 경우 memory에 접근하기 전에 미리 base보다 낮은 쪽 base + limit보다 높은쪽을 건드리리는지 안건드리는지 확인한다. 안건드리면 ok, 건드리면 못가게 막는다. 못가게하면, 프로세스가 죽는다.
(ex: segmentation fault: 내 프로세스가 지금 다른 프로세스 영역에 접근하고 있으니까 os 입장에서 실행을 막는 것: trap to operating system illegal addressing error)
■ Relocation Register
실제 나는 0번지라고 생각하지만, 사실 100번지라고 MMU에서 걸러줌. 실제로 memory엔 영역을 차지하고 있음. 이를 통해 메모리 관리를 진행함.
■ Contiguous Memory Allocation
메모리는, 하나의 프로세스는 메인 메모리에 순서대로 연속적으로 올라간다. 그래야 Memory Protection의 base, base + limit 방식을 통해 메모리 보호가 가능하다. (다른 프로그램이 내 프로그램에 침범 못하도록) 하지만 연속적으로 할당하다보니 Hole 문제가 발생하기 시작함.
메모리 할당 - 프로세스에 메인 메모리를 할당하는 방법
연속 메모리 할당 - 각 프로세스는 다음 프로세스에 인접한 메모리의 단일 섹션에 포함됨.
Hole
- 처음엔 Process 5, 8, 2가 순서대로 전부 들어가 있지만 8이 끝나고 가운데가 텅 비게 됨. > process 9가 수행되는데 그 칸만큼만 차지 > process 5가 끝남 > 메모리가 띄엄띄엄 비어있는 memory hole 현상이 발생. - 프로세스를 종료하면 해당 파티션이 해제되기 때문에 사용 가능한 메모리 블록이 메모리 전체에 흩어져 있음.
■ Storage Allocation
hole이 한개가 아니라 여러개라면?
새로운 프로세스가 실행이 되는데 그것을 어디에 할당할 것인가?
First fit
- 순서대로 찾아가다가 내가 넣을 수 있는 영역에 (무지성으로) 프로세스를 넣는 것
순차적으로 P3를 <Initial>에, P4를 <P3>에 P5를 <P4>에 넣음 → P6를 넣을 공간이 없음 → 사실 마지막 <P5> 단계의 남은 공간들을 전부 합치면 P6를 넣을 수 있음 → 하지만 프로세스를 연속적으로 할당하려하고 First Fit을 사용하려고 보니 빈 영역이 조각조각 나서 P6를 사용할 수 없음. (이 현상을 외부 단편화 (개미친중요)라고 함)
※ External Fragmentation (외부 단편화)
- 요청을 충족하는 데 사용할 수 있는 총 메모리 공간이지만 연속적이지 않음. - 스토리지 많은 수의 작은 hole로 쪼개짐 (First fit, Best fit 모두 이러한 단편화로 인해 어려움을 겪음) - first fit은 주어진 n개의 블록이 조각화로 손실된 0.5n개의 블록을 할당했다는 것을 보여줌 (1/3을 사용하지 못할 수 있음 > 50 - 퍼센트 규칙) - 압축을 통해 외부 조각화를 줄일 수 있음.
Best fit
- 가장 내가 필요로 하는 영역과 빈 영역이 적은, 빈공간을 남기지 않게 프로세스를 넣는 것
P3는 <Initial>의 Hole 3개 중 가장 크기가 비슷한 2번째 Hole에 할당. ( P4, P5도 마찬가지 ) → P6를 할당해주려니 Fist Fit과 비슷한 상황이 발생 (외부단편화 발생)
Worst fit
- 빈 공간을 최대한 많이 남기는 식으로 메모리에 프로세스를 넣는 것
제일 널널한 공간에 할당하는 것이므로 P3는 <Initial>의 어디든 들어갈 수 있지만 가장 큰 맨 밑 Hole에 들어감 (P4, P5도 마찬가지) → 이렇게 진행하니 P6를 <P5>의 두번째 Hole에 할당할 수 있게 됨 (외부 단편화가 확률적으로 제일 적게 발생하기 때문)
Compaction
- 메모리 콘텐츠를 섞어 사용 가능한 모든 메모리를 하나의 큰 블록에 배치함. (사용 가능한 메모리의 큰 구멍을 만듦) - 압축은 재배치가 동적이며 실행 시간에 수행되는 경우에만 가능.
First Fit, Best Fit, Worst Fit 상관 없이 내가 프로세스를 할당해야하는데 공간이 부족하면 → <P5>의 빈 공간들을 하나로 모은 다음 P1, P4는 위로 올리고 P2, P5는 아래로 내려 P6가 들어갈 빈 공간을 모아준다(압축해준다).
※ 이론적으로는 제일 좋은 솔루션이지만 현실적으로 사용하기 너무 어렵다. (비용이 비쌈) 그런 이유로 OS는 Paging 기법을 사용한다.
Paging
- 연속적으로 프로세스를 할당하는게 아니라 프로세스가 사용하는 메모리 공간을 고정된 크기의 페이지로 나누어서 비연속적으로 실제 메모리에 할당하는 것. (외부 단편화 해결)
- 프로세스의 물리적 주소 공간은 연속되지 않을 수 있음 (외부 단편화, 압축의 필요성을 피할 수 있음)
- 논리 메모리(logical memory)를 같은 크기의 페이지 블록으로 나눔. - 물리 메모리(physical memory)를 프레임이라고 하는 고정된 크기의 블록으로 나눔 (크기는 2의 전력으로 512byte ~ 16MB 사이)
- 논리 주소를 실제 주소로 변환하기 위해 페이지 테이블을 설정함. - 프로그래머는 메모리를 하나의 공간으로 봄 (사실 사용자 프로그램은 외부 단편화를 피하기 위해 다른 프로그램도 보유하는 물리적 메모리 전체에 분산되어 있음.)
■ Paging Hardware
p의 페이지 번호를 추출하여 페이지 표에 색인으로 사용 > 페이지 테이블에서 해당 프레임 번호 f를 추출 > 논리 주소의 페이지 번호 p를 프레임 번호 f로 바꿈.
page를 만든다는것?
= Virtual memory 영역과 Physical Memory 영역을 분리된다는 것. 어떤 페이지가 어떤 메모리 프레임에 올라가 있는지 항상 tracking하는 테이블이 존재해야한다. 그것을 page table이라 부른다.
※ 프레임: 물리 메모리를 일정한 크기로 나눈 블록(메모리에 올라가 있는 페이지같은 개념)
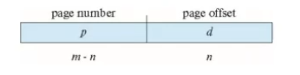
※ Address Translation
page table은 하드웨어로 구성이 되는데 내가 어떤 메모리에 접근하려 하는 경우 그 주소를 나누고 page offset은 놔두고 page number를 찾은 다음 그에 해당되는 frame number를 찾아서 찾았던 offset과 연동시켜 새로운 physical address를 생성시킨다.
줫나중요!! Page number (p): 물리적 메모리에 있는 각 페이지의 기본 주소를 포함하는 페이지 테이블에 인덱스를 사용함. Page number (d): 메모리 단위로 전송되는 실제 메모리 주소를 정의하기 위해 기본 주소와 결합됨
Virtuall Address(VA)를 Physical Address(PA)로 바꾸면 메모리 공간 활용으로는 best 하지만 page table이 너무 커져버림. 현실적으론 이 방법은 사용하지 못하기 때문에 VA와 PA가 어느정도 크기를 가지고 해당 공간의 내부적으로 까지는 분리하지 말자고 정해둔다. 그 크기 안에 있는 offset(주소)들은 굳이 address translation에 참여하지 않는다. (페이지 내에 상대적인 주소만을 가리키기 때문) → page offset(d)으로 빼고 실제 page number(p)만 찾아서 frame number로 바꿔 physical address로 만듦.
1:12:11 다시 정리.
Q: page size가 1kb이다. 이 상황에서 page number를 찾아봐.
Virtual Memory(2)
■ Translation Look - aside Buffer [TLB] 개줫나 중요
주소 변환에는 두 개의 메모리 액세스가 필요. - 하나는 페이지 테이블용이고 다른 하나는 실제 데이터용.
Translation Look-aside Buffers (TLBs) - 빠른 검색을 위한 특별한 fast-lookup 하드웨어 캐시
TLBs는 일반적으로 작음 ( 64 ~ 1024 항목)
TLB Miss - 페이지 번호가 TLB에 없음을 의미.
페이지 테이블 워크 - 페이지 테이블에서 실제 프레임 번호를 찾아 값을 TLB miss에 TLB로 다시 채움. - 엄청난 수의 사이클이 소요. - TLB miss가 성능을 크게 감소시킴
모든 컨텍스트 스위치에서 tlb 플러시 필요 - 컨텍스트 전환(Context switching)은 많은 수의 TLB miss를 의미 - 주소 공간 식별자 (ASIDs)
페이징엔 페이지 테이블이 반드시 필요하다. 하지만 physical memory가 너무 멀고 너무 크다.
※ Translation을 한다는 것 => 메모리에 접근해서 page table을 뒤져보고 거기서 다시 frame number를 찾아 또 한번 memory에 접근한다. 이는 너무 비효율적! 이를 해결하기 위해 만든것이 TLB
page table: 모든 page에 대한 정보가 있다. TLB: 잘 사용하는 정보만 있다. 그래서 반드시 Page number와 frame number가 짝으로 있어야한다.
page table은 page number가 공식적으로 존재할 필요가 없다. page table의 indexing이 page number이기 때문이다. 하지만 TLB는 모든 정보를 저장하고 있지 않기 때문에 page number 중 어떤 정보가 있는지 알아야하기 때문에 page number와 frame number가 둘 다 들어가 있어야 한다.
■ Valid Invalid bit
모든 page가 전부 메모리에 있는것은 아니다. (사용하지 않는 것을 메모리에 올릴 필요 없기 때문)
현재 page가 실제로 memory에 있는지 없는지 확인하는 bit이 필요하다. 이것을 valid bit이라고 부른다.
→ 그림에서 page table의 i (valid bit)가 꺼져있으면, 실제 메모리(우측 그림)엔 없음.
프로그램이 메모리(page table)에 없는 page를 읽으려 시도. (근데 page가 없는 경우 > page fault)
페이지 오류가 발생하여 OS에 트랩.
빈 프레임과 백 스토어에서 page를 찾음. (사용 가능한 프레임이 있는 경우).
페이지를 프레임으로 swap. (페이지가 처음 생성되어 페이지가 백 스토어에 저장되지 않는 경우 이 단계를 수행)
페이지 테이블에 있는 페이지의 유효한 비트를 v로 갱신. (다음번부터는 해당 page는 존재해야하기 때문)
페이지 장애를 일으킨 지침을 다시 시작.
■ Page Replacement
메모리는 한정적이지만, 가져와야하는 page가 많은 경우가 존재.
이 경우 page를 쫒아내야함. 그렇다면 어떤걸 쫒아내는가? 이 과정: replacemeny policy (교체정책)
디스크에서 원하는 페이지 위치를 찾음.
빈 프레임을 찾음 (free frame의 경우, 빈 프레임이 없는 경우 교체할 대상 프레임을 선택).
원하는 페이지를 free freame에 넣음.
지침을 재시작하여 프로세스를 지속.
Page Replacement: Optimal Algorithm
- 가장 오랫동안 사용하지 않을 page를 바꾸다 - page 결함률이 가장 낮음. - page들에 대한 미래 예측을 요구하기 때문에, 실행하기가 어려움. > 이 이유로 실질적으로 사용하기가 어려움
Page Fault Rate: MISS 갯수(page fault 갯수)/총접근수
Page Replacement: First In First Out (FIFO)
- 가장 오래된 페이지 page를 바꿈. - 이해하고 설명하기 쉬움. (간단한 알고리즘)
- 간단하지만 성능이 나쁘고 Belady's Anomaly 발생
A가 가장 먼저 들어왔으니까 D가 들어갈 자리가 없다면 C의 A를 쫒아내고 D를 넣음
Page Replacement: Belady's Anomaly
- 프로세스에 메모리를 더 많이 할당하면 성능 저하.
- 프레임 수가 증가함에 따라 page 장애율 증가. (프레임 갯수를 늘려도 성능이 저하) > 아주 교묘하게 내가 필요한것이 먼저 쫒겨나는 상황이 발생하기 때문.
- 위와 같은 이유로 현실적으로 사용이 어려움.
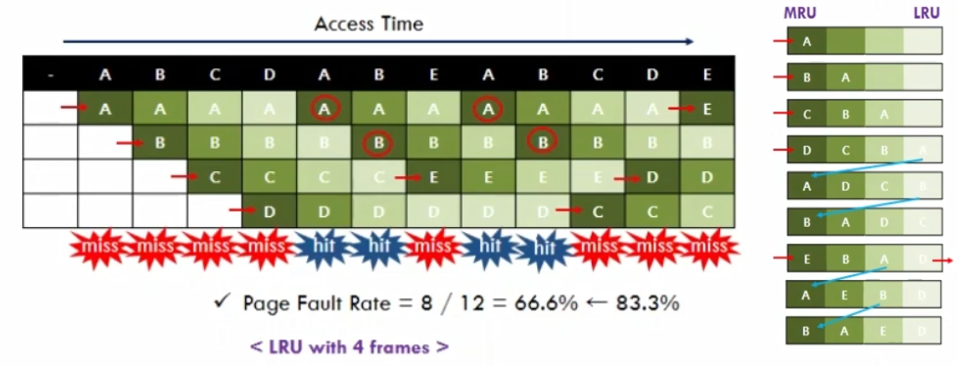
Page Replacement: Least Rencently Used (LRU)
- 가장 최근에 사용한 page가 쫒겨나지 않으며 가장 오랫동안 사용하지 않은 page가 쫒겨남
- 각 페이지에는 마지막으로 사용한 시간이 존재.
- 현실적으로 제일 많이 사용되는 Page replacement 알고리즘.
A가 맨 처음 Hit이 되는 순간 제일 중요하게 됨. (우선순위가 바뀌게 되는 것)
■ Tharshing (★★★)
- CPU가 프로세스를 실행하는 대신 페이징 입출력. - 일반적으로 CPU가 낮을 때까지 OS는 멀티프로그래밍의 정도를 높여 CPU 활용도를 극대화. (CPU 활용률이 낮으면 더 많은 프로세스가 실행될 수 있음).
CPU는 멀티프로그래밍을 수행한다고 하더라도 동시에 os가 반드시 n개를 동시에 수행하지 않음.
CPU가 쓸 만큼만 수행을 시켜줌. → Degree of multi programming
Degree of multi programming: 예를들어 일단 10개 중 3개만 실행시켜보고 CPU가 감당 할 수 있는지 없는지 판단하고 늘려나감.
감당되는지 안되는지 확인하는 방법 → Utilization
Utilization: 낮으면 CPU가 놀고있다고 판단, 너무 높으면 CPU 억제.
※ Utilization만으로 관리를 하다보니 문제점이 발생.
A,B는 N 메모리 영역에 같이 들어갈 수 있지만 M 메모리 영역은 너무 부족하다.
A가 수행될 땐 A에 대한 page가 메모리에 올라가야함. 모든 page를 올리기에 부족하기 때문에 B를 쓰다가 A를 쓰면 page fault가 발생함. B도 마찬가지. page fault는 CPU 입장에서 엄청난 시간을 잡아먹음. page fault가 발생하는 동안 CPU는 아무것도 할 수 없게 됨. (=status에서 wating 상태에 빠지는 것) 그럼 자연스럽게 cpu utilization도 낮아지게 됨. 이러한 상황 떄문에 OS는 CPU가 놀고 있다고 판단하여 프로그램을 수행하도록 할당함. (C라는 새로운 프로그램을 실행 시키겠다는 의미) 그럼 M이라는 작은 공간에 A, B, C 3개의 page가 들어가게되면서 Utilizatiom이 더 떨어짐. 반복하다가 시스템이 멈춰버림. 이러한 현상을 Thrashing이라고 함.
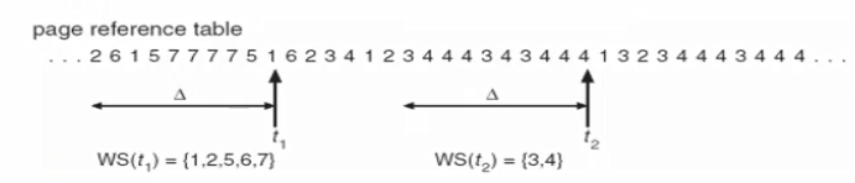
Thrashing을 해결하기 위해 Working Set Model이라는 것이 존재.
※ Working Set Model
A가 수행하기에 필요한 적당한 양의 메모리를 찾고 메모리 양이 부족하면 프로그램을 실행하지 않는다.